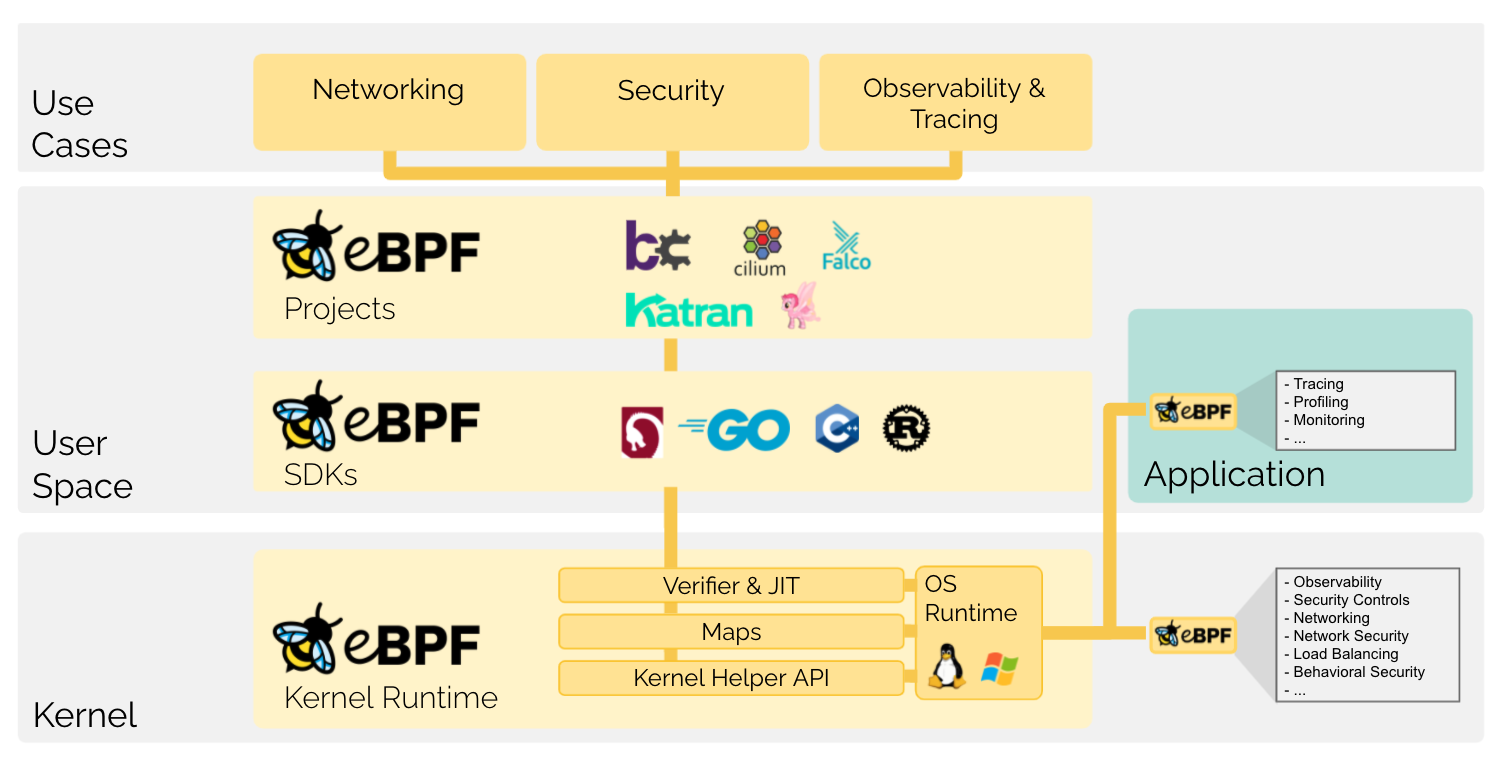
eBPF (which is no longer an acronym for anything) is a revolutionary technology with origins in the Linux kernel that can run sandboxed programs in a privileged context such as the operating system kernel.

BPF is a highly flexible and efficient virtual machine-like construct in the Linux kernel allowing to execute bytecode at various hook points in a safe manner.
内核大神Brendan用了比喻的说法,更加形象地介绍了这个技术。eBPF对于Linux就相当于Javascript对于HTML一样。Javascript给静态的HTML网站带了了动态的内容和效果,已经丰富的交互能力。Javascript程序运行在一个虚拟机的安全沙盒中。eBPF也对Linxu内核提供了类似的功能,程序员可以通过编写字节码,从而让程序工作在内核的沙盒环境中。eBPF更像是内核中Javascript的V8虚拟机引擎。直接编写eBPF非常困难,因此一般都会采用bcc,bpftrace这些框架来编写eBPF程序。如今,也可以采用Golang,Rust和Python的框架进行eBPF编程。
eBPF是一个非常重要的将内核态功能映射到用户态的技术,最早是用于对内核中的程序进行监控产生的。如今已经被广泛应用于各类需要挂入内核以提供内核监控,以及提高性能的应用中。主要应用于以下几类应用领域:
- Security 通过直接提取和解析内核中socket的数据报文,可以提供新型的安全预警和过滤机制。通过eBPF可以构建一个全面透明和可控的操作系统内核级的安全系统,提高非常高级别的安全防护机制。
- Tracing & Profiling 只是BPF技术最早被发明出来时的使用场景和用途。通过eBPF可以将探针插入内核态以及用户态的应用中去。从而追踪和分析应用程序的运行时信息和状态,提供深度的程序运行情况的洞悉。通过这个技术,我们能够更加深入分析系统的性能,提供调优和缺陷查找能力。
- Networking 结合了可编程性和高性能的特点,eBPF天生适合对网络数据报文进行预处理和分析,能够在内核层级对网络协议和数据进行高效处理和分发,提高网络应用的性能和可靠性。
- Observability & Monitoring 通过eBPF可以不依赖操作系统提供的静态计数器和监控机制。直接获取内核中的定制化的度量指标,并能够通过事件驱动的方式通过广泛的数据来源进行系统监控。
是工具中一个专门用来追踪Linux系统中所有TCP连接情况的程序,采用了eBPF技术实现。运行tcplife后的结果如下:
PID是进程ID,发送和接收字节数(TX_KB,RX_KB),持续时间(MS)。这样的程序也可以用一般的内核代码编写,但是如果是这样的话可能永远不可能达到如此的性能和安全性。首先原生内核程序会过滤每一个网络报文,而不是只是TCP协议报文,这就会增加大量额外开销。同时抓取所有的数据包也对安全性产生了一定的隐患。
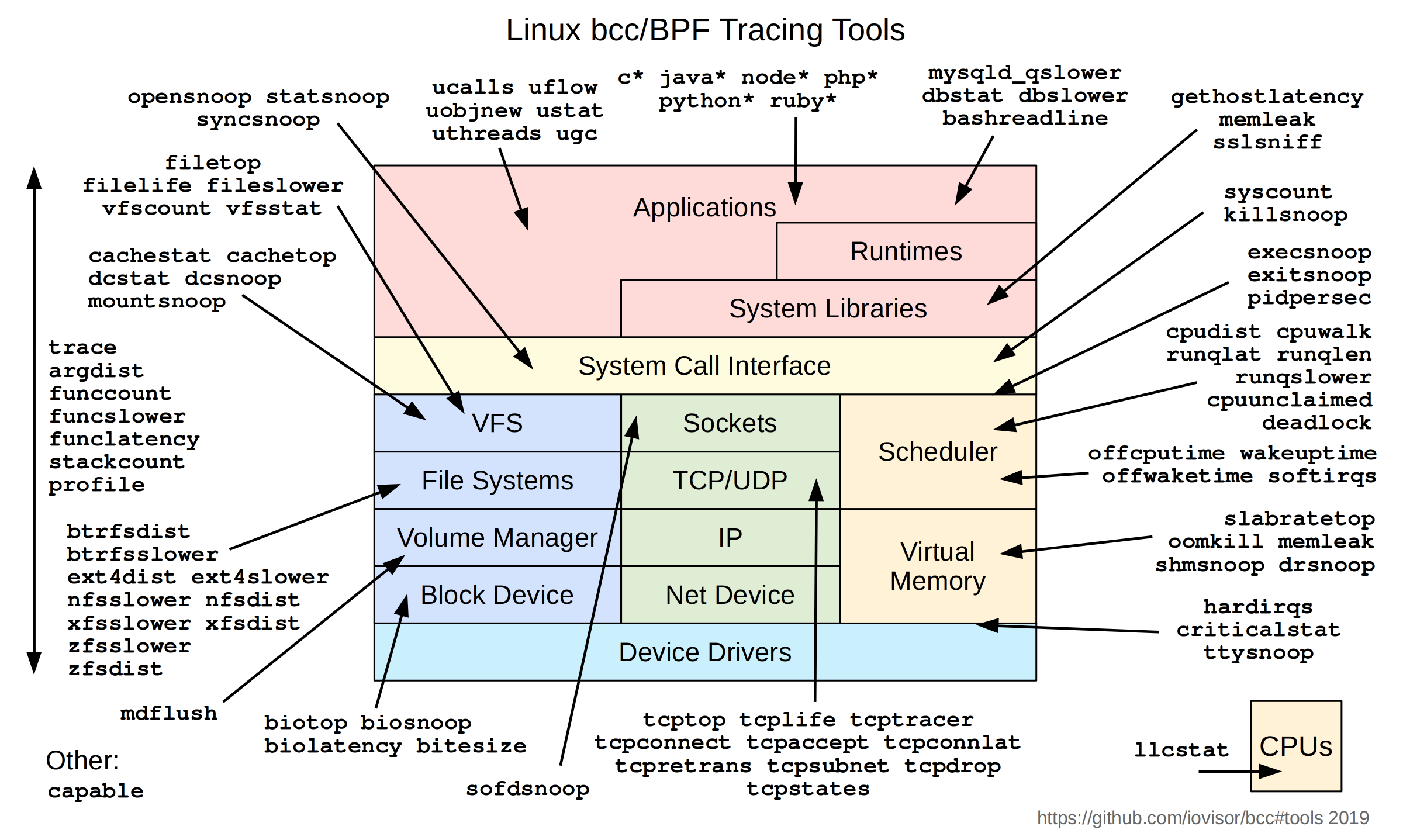
本身提供了70多个可以直接使用的基于eBPF技术的工具,涵盖了内核层的很多功能和追踪。这些工具如下图所示:这些工具的用法可以通过https://github.com/iovisor/bcc查看
Brendan Gregg提供的bpftrace教程:The bpftrace One-Liner Tutorial。写的非常详细。在这里选取一部分进行解释和学习参考用。
- 查询Probe
-l用于根据查询条件列出所有的应用程序探针点(Probes),其中探针点(Probes)是指的一个可以抓取时间数据的测量点
- 插入触发点
如上面的命令所示,BEGIN就是在程序的前面加入一个probe触发点,可以再此处定义变量或者输出一些文字。这里是输出一个hello world字符串。
- 打开文件
上面的命令在呼叫系统调用的时候触发追踪事件,将进程名称和系统调用中的文件名参数打印出来。运行后,我们可以看到所有调用了打开文件openat系统调用的程序都被追踪并输出了文件名。除了,我们也可以获得(进程ID)和(线程ID)。
- 统计进程数量
上述代码运行后会显示目前运行的某个进程名称的总数。
@用于设定一个map,@后可以跟一个map名称,这里没有设定名称。中括号[]里面的变量作为map的key值。是一个map的方法,用于统计某个map中某个key出现的次数。
- 输出read()的bytes数分布直方图
这个是一个过滤器,用于过滤查询条件,限制范围。这里直接设置了进程的ID。通过对read结束时ret参数的统计,来获得最终读取的字节数。然后通过map的直方图方法hist对数据进行统计。除了hist以外,map方法还有前面用过的,-线性直方图,,,以及。
...剩下的部分可以直接参考原文。
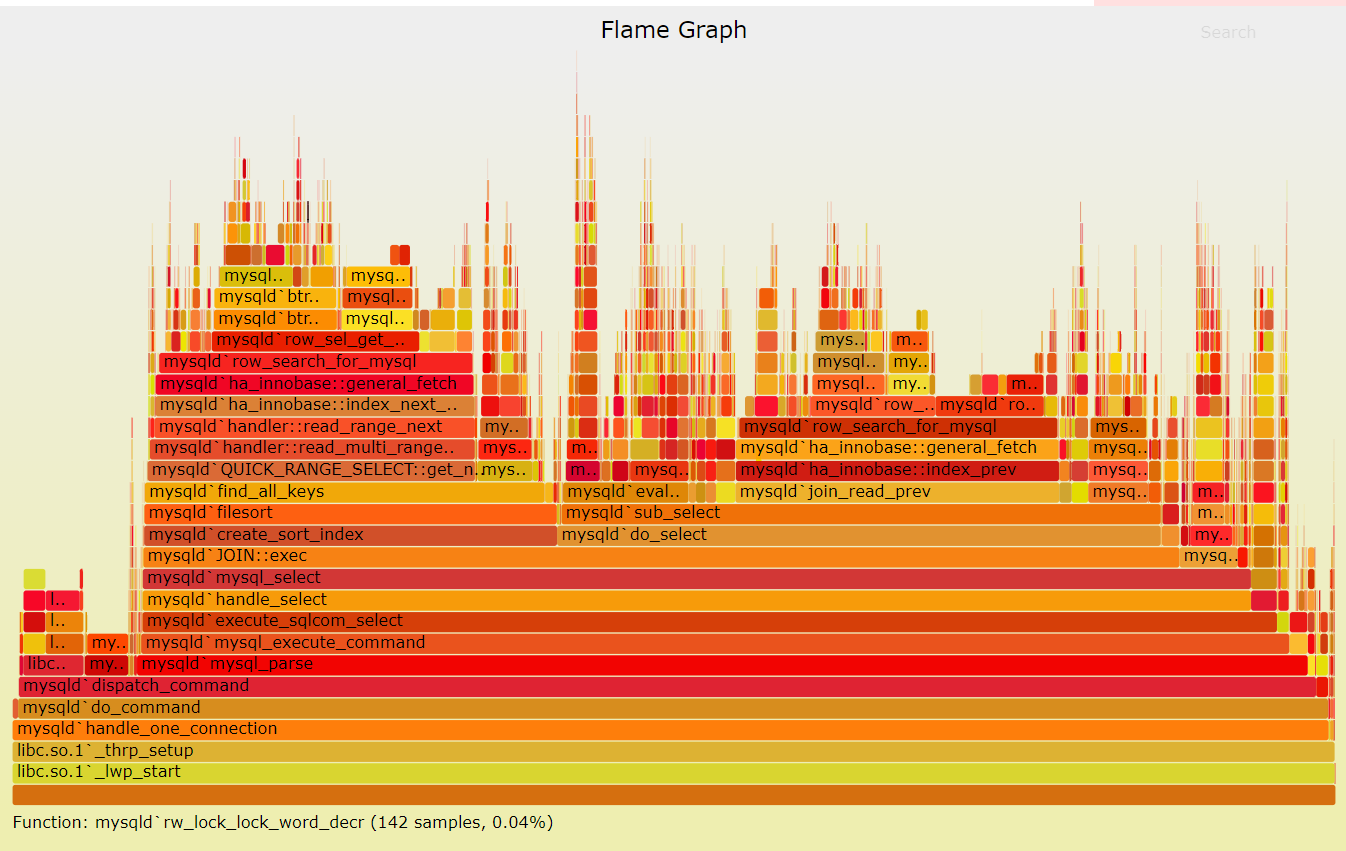
性能火焰图,上述的火焰图广泛用于系统性能评估和调优,也是通过eBPF技术实现的。上述是Mysql的CPU火焰图,显示了各个层级的stack的CPU占用。
目前基于Go的eBPF框架有Dropbox、Cilium、Aqua和Calico这几个库,通常这些库完成的工作也是将eBPF程序和Map载入内核,通过文件描述符和Map进行关联。并且可以和eBPF Map进行交互(CRUD)操作。不同的库实现形式,使用范围不尽相同。
- Calico用bpftool和IProute实现的CLI做了一个Go的包装
- Aqua实现了对libbpf这个库的Go包装
- Drobox只支持了一部分功能,API比较简洁
- IO Visor开发的gobpf是bcc的Go语言版本。
- Cilium维护了一个纯Go语言的BPF库,将eBPF系统调用抽象为Go接口
更具《Linux内核观测技术》中的说法,主要更具功能将BPF程序分成两种类型,分别是跟踪和网络。
这类程序用于更好的了解系统和应用程序当前的状态和行为。主要能够提供实时的系统行为和硬件的直接信息。另一方面可以访问特定应用程序内存区域,跟踪并提取运行进程中的信息。此外,还可以直接访问为每一个进程分配的资源,其中包括文件描述符,CPU和内存等信息。
网络络包追踪和过滤是BPF程序最开始被设计出来时的应用方向。通过BPF我们可以对网络流量数据包处理的各个阶段进行监控和处理,能够在内核层级实现对于数据包的流量控制,安全检查,过滤,甚至可以跳过全部或者部分内核网络协议栈,直接处理网络数据并转发。提供了对于网络底层的强大追踪和控制能力。
上面是根据主要功能类型将BPF程序进行了分类,下面会根据eBPF程序的具体功能更详细的分类介绍
- socket过滤器程序
- Kprobe程序
- 跟踪点程序
- XDP程序
- Perf事件程序
- cgroup套接字程序
- cgroup打开套接字程序
- socket选项程序
- socket映射程序
- cgroup设备程序
- socket消息传递程序
- 原始跟踪点程序
- cgroup套接字地址程序
- socket重用端口程序
- 流量解析程序
- 其他BPF程序
全部程序种类列表如下:

上图简要描述了eBPF的执行流程,BPF需要用C语言进行编写,通过LLVM/Clang编译为BPF字节码,运行时通过用户空间中的程序(C/Golang/Rust/Python...)将字节码注入内核态的BPF虚拟机中,首先会通过BPF验证器(Verifier)检查代码的正确性和安全性,通过后才能够给到JIT进行编译,生成本地可以执行代码。这些代码是通过BPF的挂载点和某个内核函数绑定,并在内核函数调用的时候被启动执行。BPF和用户态数据的传递是依靠BPF Maps机制执行的,这个Map支持多种数据类型,通过Map可以将监控数据实时传输到用户态程序,用户空间程序也可以通过Map将运行时的参数等传递给EPF程序。
BPF最神奇之处就是它可以通过通过消息传递的方式,监控内核态程序的状态以及影响和改变内核态程序的执行过程,而不需要修改内核程序本身。这是一个非常强大的工具,因此被称为Linux内核中最神奇的技术,没有之一。
另外一点需要强调的是,BPF程序运行在内核中,而且每次运行必然是事件驱动的。例如:
- 在网络设备或者驱动的数据入口挂载的BPF程序,会在每次有数据包接收时被运行。
- kprobe探针类型的BPF程序会在每次某个挂载函数地址运行时被触发,并运行。
一个eBPF程序可以使用的资源包括11个64位寄存器(可以分成32位子寄存器),一个程序计数器以及一个512byte的BPF栈空间。其中寄存器名称为。其中寄存器是只读寄存器,储存一个帧地址指针,用于访问BPF的栈空间。其余四个寄存器都是通用可读写的寄存器。
BPF程序可以调用内核中预定义的帮助函数,这些帮助函数只会定义在内核(core kernel)中,而不可能存在与任何模块(modules)里。调用帮助函数是各个寄存器功能设定如下:
- 储存帮助函数的返回值
- 保存帮助函数的调用参数
- 帮助函数预留的寄存器
BPF设计的寄存器配置能够被目前主流的任何CPU架构满足,因此,通常BPF寄存器都是和实际的硬件寄存器一一对应的。JIT只需要处理功能调用指令,而不需要关心参数和返回值的存放地址(总是在固定的寄存器中)。这使得运行BPF帮助函数的性能和效率非常高。不过这也造成帮助函数的限制,那就是不支持6个和6个以上参数。
中保存的返回值定义,会由于BPF程序类型的不同而有区别。在执行BPF程序前,寄存器通常保存的是程序的上下文信息(context),context指的是BPF程序的运行参数(类似C语言中argc/argv运行参数对)。BPF只能有一个context,context是由程序类型决定的。例如网络程序的context是内核网络数据报文包()作为入参。
BPF程序都是基于64位处理的,主要是为了兼容主流的64位架构以及64位数表示的指针类型。BPF程序支持尾部调用(tail call)用于从一个BPF程序跳转到另外一个BPF程序执行,这种内联上线为33个调用。这个功能通常用于将BPF程序分成不同的执行阶段。
需要注意的一些限制
早期的cBPF程序指令数量限制在4096条,从5.1版内核开始,eBPF程序的指令数量提升到一百万条。内核中的BPF检查器通常会拒绝含有循环操作的字节码,这是由于BPF程序是运行于内核中的,检查器必须要确保内核运行的稳定性和安全性。
BPF程序的spilling/filling
由于寄存器数量的限制,有时候需要将寄存器中保存的参数复制到BPF栈空间中,这个操作称为spilling,而将栈空间的参数写回参数寄存器中的操作称为filling。
目前为止,BPF拥有87条不同的指令。每条指令都有相同的长度和结构。大数端系统的指令结构如下:

其中和都是有符号类型的数据。op定义了实际的操作,和 提供了额外的寄存器使用信息,off在某些指令中用于设置地址或者栈空间的偏移量(offset)或者是跳转指令的位置。设置常量或者直接使用的值。本身也有不同部分构成,前四为是指令code,一位source标志和三位指令类型代码。
目前BPF支持的系统架构包括:x86_64arm64ppc64s390xmips64sparc64和arm。不同架构都有专门的内核eBPF JIT编译器。所有的BPF操作都通过系统调用完成。包括加载BPF字节码程序到内核以及操作Maps进行数据交互。
BPF帮助函数(helper functions)
内核中定义了很多帮助函数,用于获取/加载数据到内核。不同的BPF程序类型通常只能调用一部分对应的帮助函数。根据使用的参数数量不同,内核中提供了不同的帮助函数的宏定义。更新Map元素的帮助函数定义如下:
帮助函数和系统调用类似,函数标准定义如下:
eBPF程序一般有两个部分组成
- 内核中运行的eBPF程序,用C语言编写,编译为内核文件。通常需要使用clang/llvm编译为elf格式的文件。
- Go语言编写的用于加载和测试eBPF的程序,在用户态运行,用于配置和读取eBPF程序数据。
我们需要安装以下一些工具:
最近一些年,由于eBPF的发展比较快,Linux内核的更新速度也非常快,eBPF在不同的内核版本中还是有不少的兼容性和功能上的区别,建议最好是使用比较新的内核版本v5.10以上。我们在编写和测试eBPF程序前应该确认当前的内核版本,笔者的开发系统:

- 安装llvm编译器,clang 9.0以上, 下面的代码是安装llvm和clang
安装完整的开发环境如下:
在示例程序中我们采用Cilium开源的ebpf-go库进行程序生成和内核加载。我们可以从https://github.com/cilium/ebpf下载这个项目。实际开发并不需要完整的项目代码,将examples文件夹中kprobe文件夹中的内容拷贝到一个测试用的文件夹中。我将Kprobe探针程序放到这个文件夹中,另外需要将headers文件夹拷贝到文件夹中,所有c的bpf库调用都要依赖头文件,BPF程序不允许引用任何外部库和模块。我们在kprobe文件夹中只需要保留main.go和kprobe.c这两个文件。首先设置编译工具clang:
然后运行go mod init,生成mod文件并下载所需的go的ebpf库
生成字节码和辅助的go程序,并编译和执行
我们可以看到通过generate我们生成了BPF程序的字节码文件和辅助的go程序文件。编译后生成kprobe程序,运行后,效果如下:
这个程序就是每两秒显示一次execve系统程序调用的总次数。
eBPF程序的代码如下:
代码主要是创建了一个map对象kprobe_map,用于内核于用户空间程序数据交换,这个map是BPF_MAP_TYPE_ARRAY类型的,最大元素1个。程序非常简单,就是每次系统调用被调用,探针BPF程序就能够触发并将map中的值+1。
以上就是本篇文章【Linux内核超级装备eBPF技术详细研究】的全部内容了,欢迎阅览 ! 文章地址:http://sicmodule.glev.cn/quote/9260.html 行业 资讯 企业新闻 行情 企业黄页 同类资讯 网站地图 返回首页 歌乐夫资讯移动站 http://sicmodule.glev.cn/mobile/ , 查看更多